Таблицы[править]
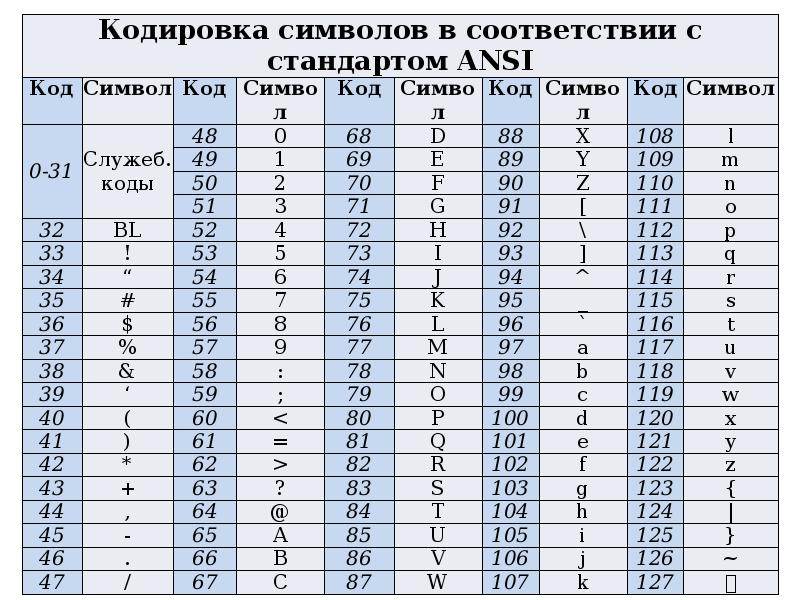
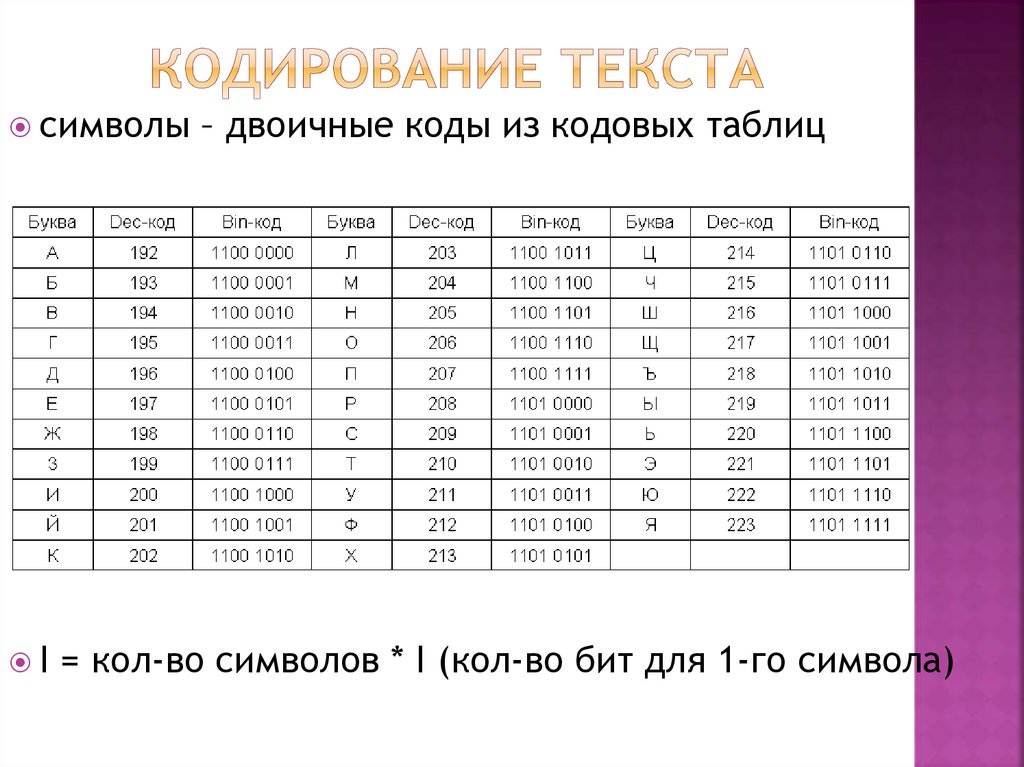
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251 (синоним CP1251)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Њ40A | Ќ40C | Ћ40B | Џ40F |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | њ45A | ќ45C | ћ45B | џ45F | |
| A. | A0 | Ў40E | ў45E | Ј408 | ¤A4 | Ґ490 | ¦A6 | §A7 | Ё401 | A9 | Є404 | AB | ¬AC | AD | AE | Ї407 |
| B. | °B0 | ±B1 | І406 | і456 | ґ491 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | є454 | BB | ј458 | Ѕ405 | ѕ455 | ї457 |
| C. | А410 | Б411 | В412 | Г413 | Д414 | Е415 | Ж416 | З417 | И418 | Й419 | К41A | Л41B | М41C | Н41D | О41E | П41F |
| D. | Р420 | С421 | Т422 | У423 | Ф424 | Х425 | Ц426 | Ч427 | Ш428 | Щ429 | Ъ42A | Ы42B | Ь42C | Э42D | Ю42E | Я42F |
| E. | а430 | б431 | в432 | г433 | д434 | е435 | ж436 | з437 | и438 | й439 | к43A | л43B | м43C | н43D | о43E | п43F |
| F. | р440 | с441 | т442 | у443 | ф444 | х445 | ц446 | ч447 | ш448 | щ449 | ъ44A | ы44B | ь44C | э44D | ю44E | я44F |
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| A. | A0 | ¡A1 | ¢A2 | £A3 | €20AC | ¥A5 | ¦A6 | §A7 | Ё401 | A9 | №2116 | AB | ¬AC | AD | AE | ¯AF |
| B. | °B0 | ±B1 | ²B2 | ³B3 | ´B4 | µB5 | ¶B6 | ·B7 | ё451 | ¹B9 | ºBA | BB | ¼BC | ½BD | ¾BE | ¿BF |
Кодировка CP1251-k (KazWin, казахская кодировка)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ұ4B0 | Ғ492 | ‚201A | ғ493 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Ө4E8 | ‹2039 | Ң4A2 | Қ49A | Һ4BA | Ү4AE |
| 9. | ұ4B1 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | ө4E9 | ›203A | ң4A3 | қ49B | һ4BB | ү4AF | |
| A. | A0 | Ў40E | ў45E | Җ496 | ¤A4 | Ҳ4B2 | ¦A6 | §A7 | Ё401 | A9 | Є404 | AB | ¬AC | AD | AE | Ї407 |
| B. | °B0 | ±B1 | І406 | і456 | ҳ4B3 | µB5 | ¶B6 | ·B7 | ё451 | №2116 | є454 | BB | җ497 | Ә4D8 | ә4D9 | ї457 |
Кодировка Windows-1251 (чувашский вариант)править
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ђ402 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Љ409 | ‹2039 | Ӑ4D0 | Ӗ4D6 | Ҫ4AA | Ӳ4F2 |
| 9. | ђ452 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | љ459 | ›203A | ӑ4D1 | ӗ4D7 | ҫ4AB | ӳ4F3 |
Татарский вариантправить
Эта кодировка была официально принята в Татарстане в г.
| .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | ||
| 8. | Ә4D8 | Ѓ403 | ‚201A | ѓ453 | „201E | …2026 | †2020 | ‡2021 | €20AC | ‰2030 | Ө4E8 | ‹2039 | Ү4AE | Җ496 | Ң4A2 | Һ4BA |
| 9. | ә4D9 | ‘2018 | ’2019 | “201C | ”201D | •2022 | –2013 | —2014 | 2122 | ө4E9 | ›203A | ү4AF | җ497 | ң4A3 | һ4BB |
Виды кодировок
Существует довольно много видов, но сейчас распространены два:
UTF-8
Unicode Transformation Format — универсальный стандарт кодирования, который работает с символами почти всех языков мира. Символы могут занимать от 1 до 4 байт, такое кодирование позволяет создавать мультиязычные сайты.
Есть несколько вариантов — UTF-8, 16, 32, но чаще используют восьмибитное.
Windows-1251
Этот вид занимает второе место по популярности после UTF-8. Windows-1251 — кодирование для кириллицы, созданное на базе кодировок, использовавшихся в русификаторах операционной системы Windows. В ней есть все символы, которые используются в русской типографике, кроме значка ударения. Символы занимают 1 байт.
Выбор кодировки остается на усмотрение веб-мастера, но UTF-8 используют намного чаще — ее поддерживают все популярные браузеры и распознают поисковики, а еще ее удобнее использовать для сайтов на разных языках.
Закодированные тексты на ваших сайтах
Так как вычислительные системы понимают только переведённый в цифры текст, один и тот же материал в разных кодировках будет выглядеть для них по-разному. Эта особенность используется некоторыми для плагиата. Всё ещё есть роботы, проверяющие уникальность, которые могут не отличить текст с непривычной им кодировкой. Но если его скопировать в блокнот, он станет нечитабельным или обрастет лишними символами.

Браузер воспринимает текст сайта тоже через кодировку. Если она будет неправильно подобрана, вместо текста будут вопросы или непонятные знаки. Кодировка задается в head, в теге. В кавычках может быть любой стандарт, но utf-8 самый распространенный из них. Поэтому для своих русскоязычных проектов используйте её. Тогда ваши сайты будут корректно отображаться в любом браузере.
Чтобы детальнее разобраться с особенностями кодировки для вашего сайта, смотрите видеоуроки. В них наглядно разбираются вероятные проблемы и их решения. На портале у Михаила Русакова есть целый ряд таких уроков. Там можно найти ответы на множество вопросов по верстке сайтов.

А то, что уже умеете, сможете делать качественнее и быстрее, учась у профессионалов. Все уроки вы сможете сохранить в компьютере, просматривая при необходимости снова.
Подписывайтесь на обновления моего блога, чтобы не пропустить самое интересное. Также добавляйтесь в мою группу Вконтакте, где свежие дублируются свежие обновления. Так вы сможете видеть их прямо в своей ленте новостей.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
Совместно с двумя российскими и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.

Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
- Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.



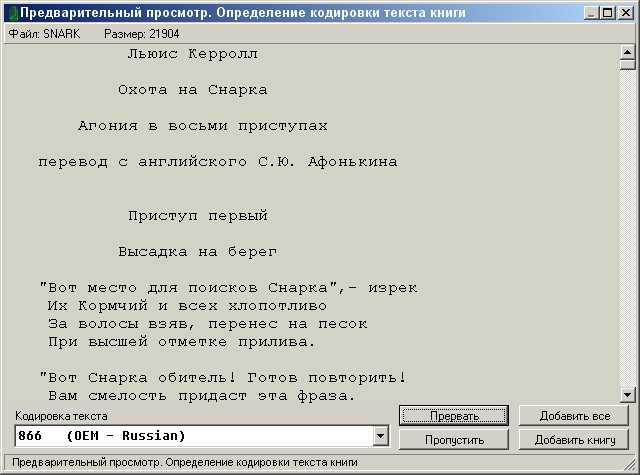
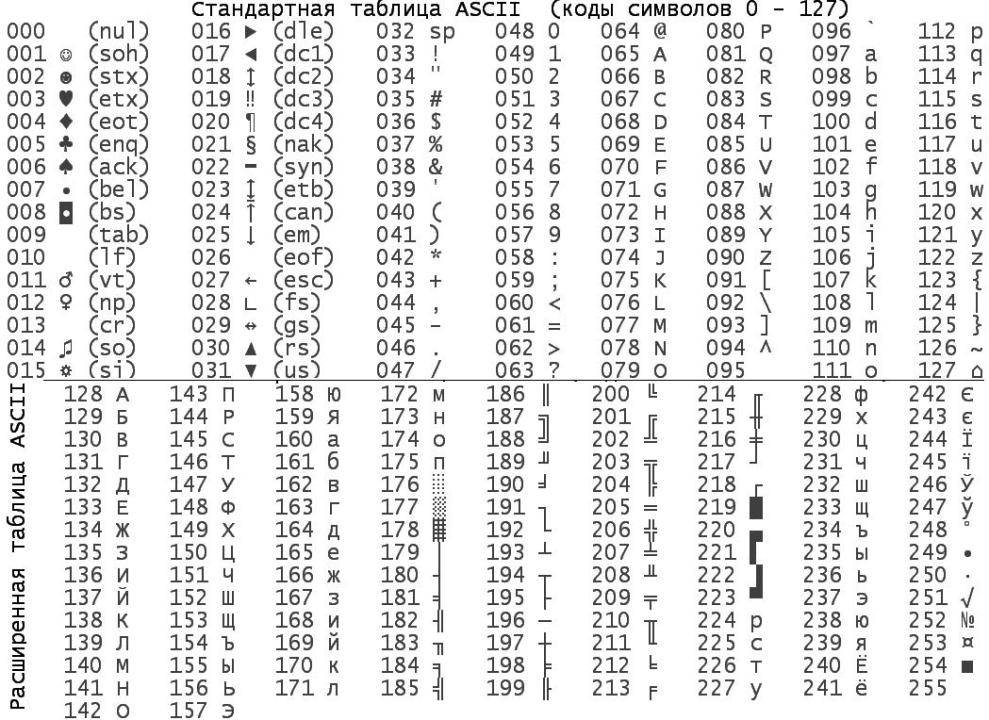
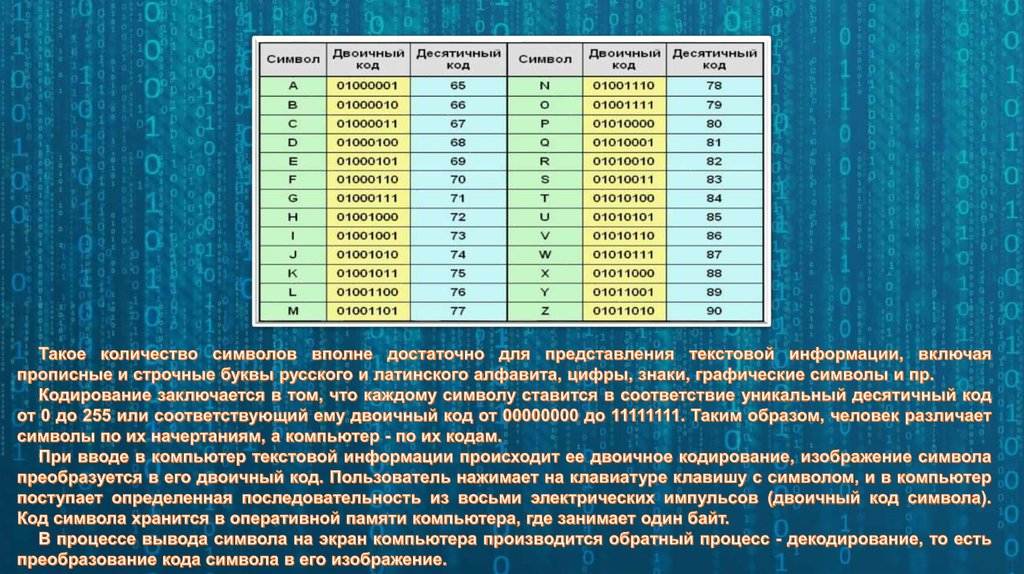
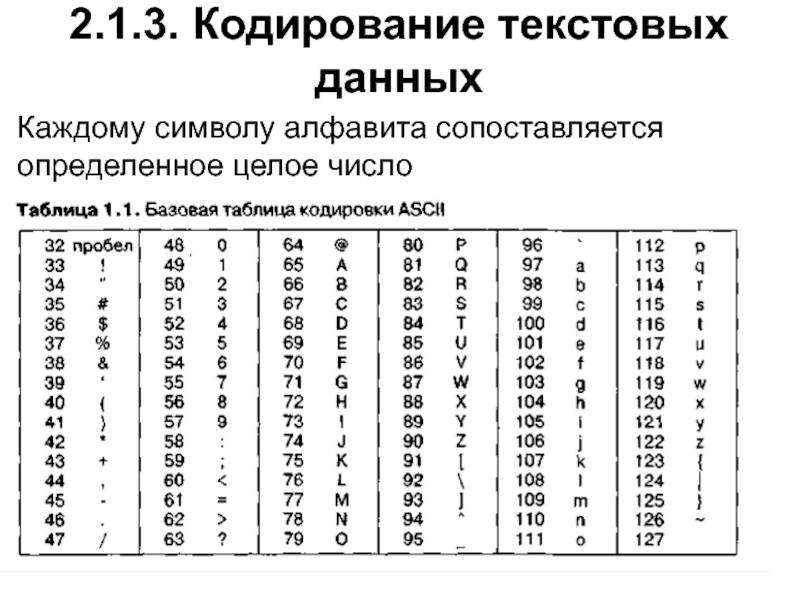
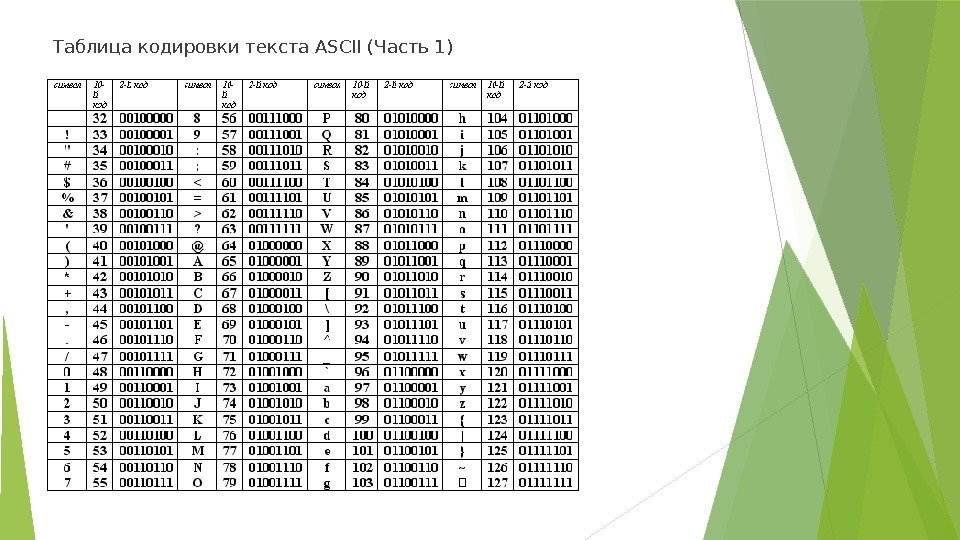
Кодировки стандарта ASCII[править]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается “читаемым”.
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
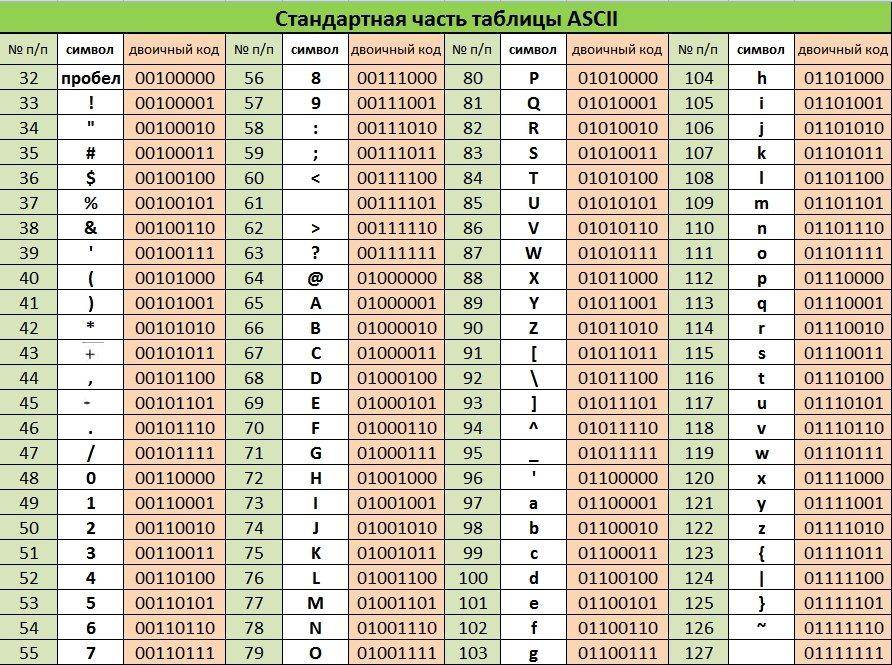
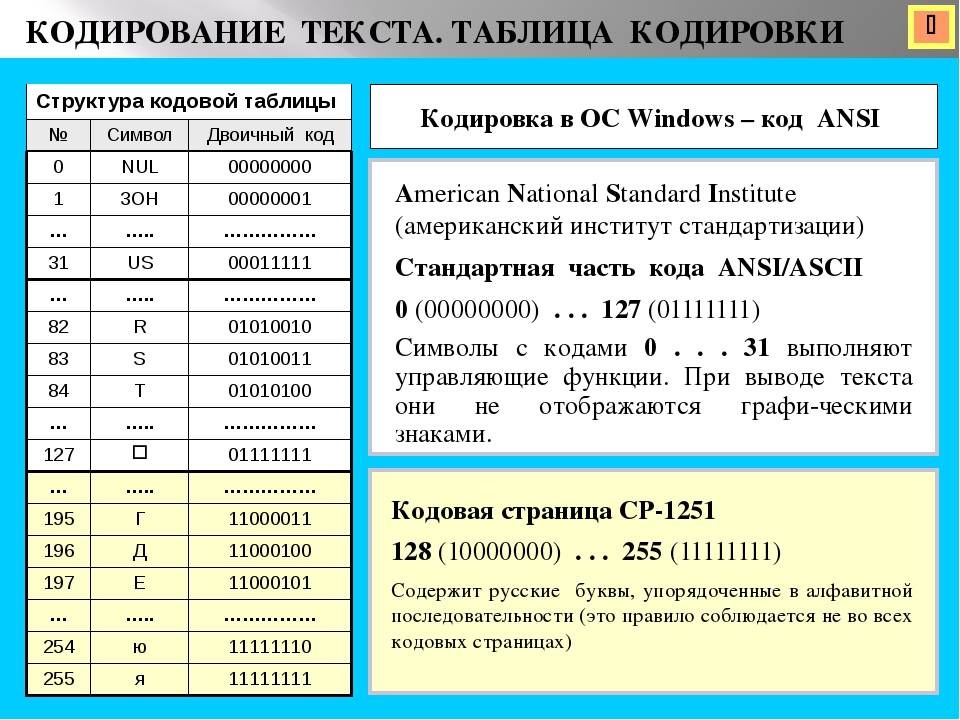
Структурные свойства таблицыправить
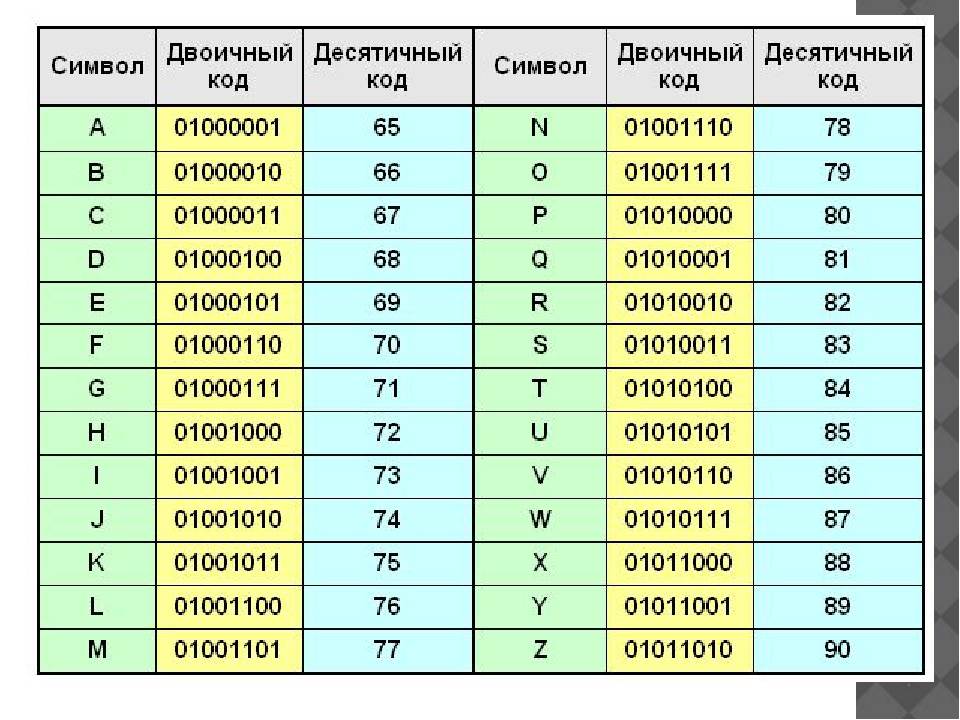
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | ” | # | $ | % | & | ‘ | ( | ) | * | + | , | – | . | ||
| 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
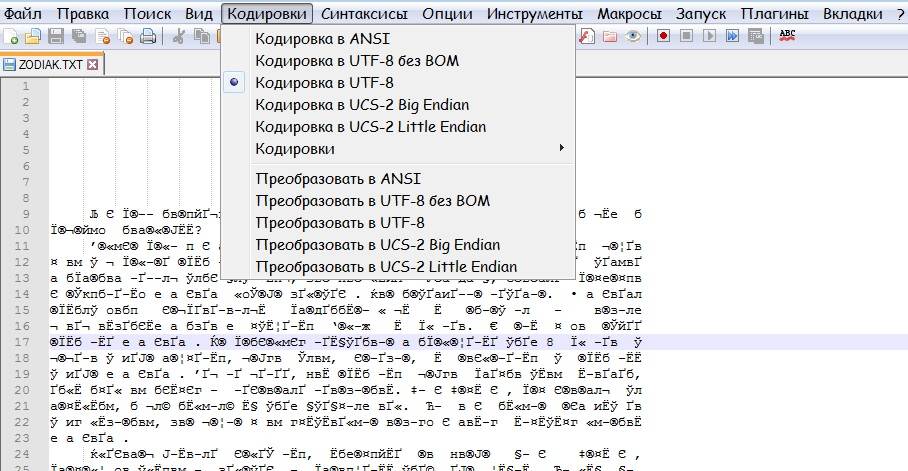
Смена кодировки веб-страниц
Если вам необходимо просмотреть страничку в интернете, а там непонятная для вас абракадабра, для решения проблемы тоже вполне подойдет Блокнот. Порядок действий:
- Сохраните веб-страницу в виде html-файла;
- Найдите ее в папке сохранения и щелкните по ней правой клавишей мыши;
- Укажите «Открыть Блокнотом», появится html-код;
- Удалите строку «Content-Type» content=»text/html; charset=utf-8″ (если вы не можете ее найти, используйте форму поиска Блокнота: «Правка» – «Найти»);
- На этом месте вставьте следующее: «charset=utf-8»;
- Перейдите к «Файл» – «Сохранить как»;
- Укажите кодировку UTF-8 (Название файла менять не надо);
- Сохраните изменения;
- Закрыв Блокнот, откройте файл в браузере (то есть просто щелкните по нему два раза левой клавишей мыши) – отобразится нормальный, воспринимаемый текст.
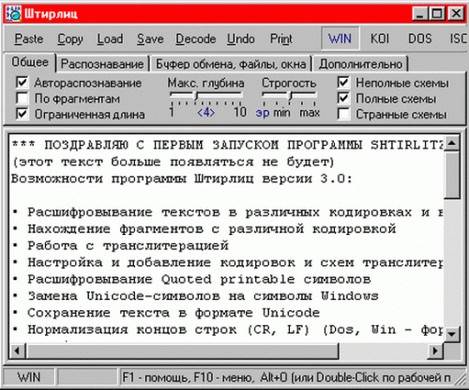
Программа Штирлиц
Это приложение предназначено для работы с русскоязычными кодировками. Текст в нее можно копировать как из буфера обмена, так и из содержимого текстового файла. Приложение реализует проверку разных схем перекодировки; если схема не обеспечивает корректного отображения всех русскоязычных слов, она отбрасывается и проверяется следующая. Также в программе Штирлиц можно создать авторскую кодовую схему и применять ее при работе с текстом, подвергшимся многократным перекодировкам.
Чтобы обрабатывать сразу несколько файлов параллельно, необходимо открывать каждый из них в индивидуальном окне программы.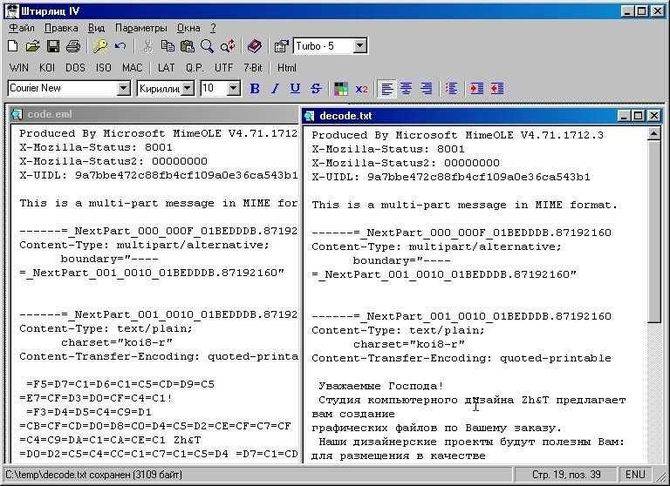
Декодер русских текстов TCODE
Этот программный продукт используется для восстановления русскоязычного текста, подвергшегося некоторым модификациям при передаче файла. Сюда относится и неподходящая кодировка. Решающее значение имеют первые 25 слов – они должны состоять из символов первой части ASCII. Скачать декодер можно на .
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или –mime, которые включают вывод строки с типом MIME. Пример:
file -i mypoem_draft.txt file -i mynovel.txt

Связанная статья: Инструкция по использованию команды file
Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
sudo apt install enca
Примеры использования:
enca mypoem_draft.txt enca mynovel.txt

В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
MS-Windows code page 1251 LF line terminators
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
enca -e mypoem_draft.txt CP1251/LF
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
enca -i mypoem_draft.txt CP1251
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
enca -m mypoem_draft.txt windows-1251

Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
enca -m -L russian mypoem_draft.txt
Чтобы узнать список доступных языков наберите:
enca --list languages
Вы увидите:
belarusian: CP1251 IBM866 ISO-8859-5 KOI8-UNI maccyr IBM855 KOI8-U
bulgarian: CP1251 ISO-8859-5 IBM855 maccyr ECMA-113
czech: ISO-8859-2 CP1250 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK
estonian: ISO-8859-4 CP1257 IBM775 ISO-8859-13 macce baltic
croatian: CP1250 ISO-8859-2 IBM852 macce CORK
hungarian: ISO-8859-2 CP1250 IBM852 macce CORK
lithuanian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic
latvian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic
polish: ISO-8859-2 CP1250 IBM852 macce ISO-8859-13 ISO-8859-16 baltic CORK
russian: KOI8-R CP1251 ISO-8859-5 IBM866 maccyr
slovak: CP1250 ISO-8859-2 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK
slovene: ISO-8859-2 CP1250 IBM852 macce CORK
ukrainian: CP1251 IBM855 ISO-8859-5 CP1125 KOI8-U maccyr
chinese: GBK BIG5 HZ
none:Универсальный декодер
Сервис отлично справляется с кириллицей. Очень популярен среди юзеров рунета. Если вы выбрали его для работы, то необходимо сделать копию текста, нуждающегося в декодировании и вставить в специальное поле. Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Если вы хотите, чтобы ресурс автоматически смог раскодировать, придется отметить это в списке выбора. Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
echo $'СТРОКА_ДЛЯ_ПРОВЕРКИ' | chardet
Или:
echo $'СТРОКА_ДЛЯ_ПРОВЕРКИ' | enca -L ru
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.

Примеры запуска:
echo $'\xed\xe5 \xed\xe0 \xe9\xe4\xe5\xed\xf3\xea \xe0\xe7\xe0\xed\xed\xfb\xe9\xec\xee\xe4\xf3\xeb\xfc' | chardet <stdin>: windows-1251 with confidence 0.970067019236
echo $'\xed\xe5 \xed\xe0 \xe9\xe4\xe5\xed\xf3\xea \xe0\xe7\xe0\xed\xed\xfb\xe9\xec\xee\xe4\xf3\xeb\xfc' | enca -L ru MS-Windows code page 1251 LF line terminators

Если возникло сообщение об ошибке:
bash: chardet: команда не найдена
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Как определить кодировку
Существует несколько способов определения:
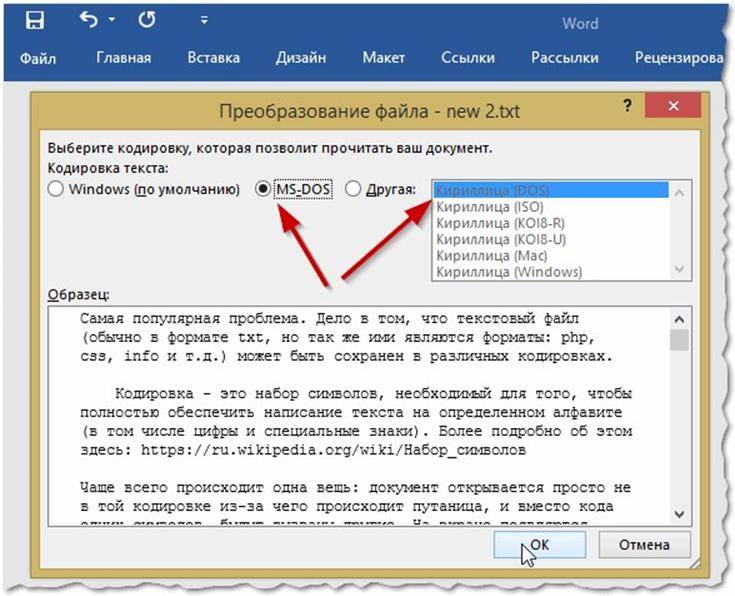
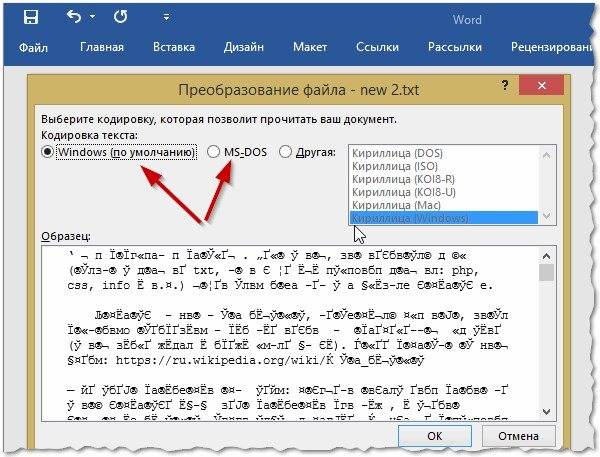
- В MS Word при открытии файла: если набор отличается от СР1251, программа предложит выбрать одну из подходящих с наибольшей вероятностью кодировок. Оценить, насколько они подходят, можно по превью образца текста;
- В программе KWrite. В нее надо загрузить документ с расширением .txt и воспользоваться настройками в меню «Кодирование»;
- Открыть файл в браузере Mozilla Firefox. При корректном отображении в меню «Вид» ищем кодировку. Искомый вариант – тот, напротив которого стоит флажок. Если содержимое отобразилось с искажениями, проверяем разные варианты в меню «Дополнительно»;
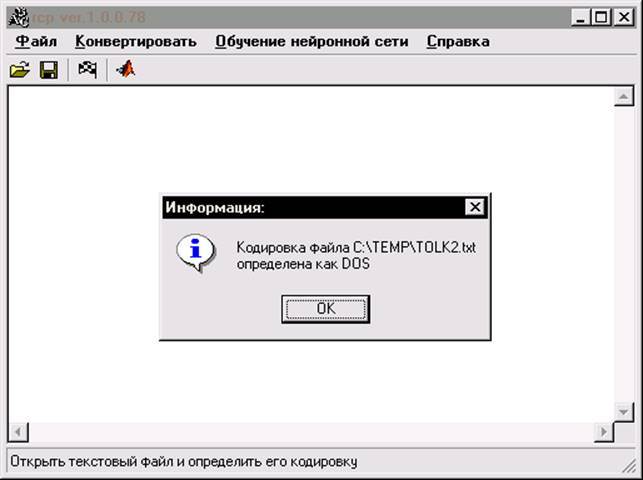
- Для работающих с Unix подойдет программа Enca.
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
HTML Символы Кодирование URL
Как определить кодировку на сайте
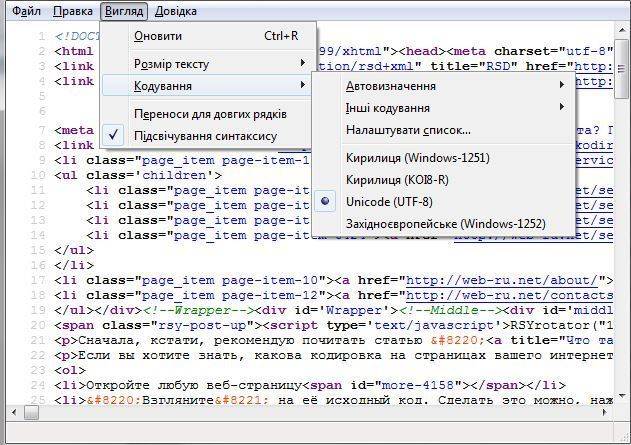
Определить кодировку страницы своего или чужого сайта можно через исходный код страницы. Откройте страницу сайта, выберите «Просмотр кода страницы» (сочетание горячих клавиш Ctrl+U» в Google Chrome) и найдите упоминание «charset» внутри тега head.
На странице сайта используется кодировка UTF-8:
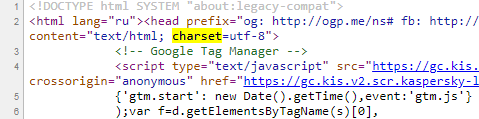 Указание кодировки в коде страницы
Указание кодировки в коде страницы
Узнать вид кодирования можно с помощью «Анализа сайта». Сервис проверяет в том числе и техническую сторону ресурса: анализирует серверную информацию, определяет кодировку, проверяет редиректы и другие пункты.
 Фрагмент анализа серверной информации сайта
Фрагмент анализа серверной информации сайта
С помощью этого же сервиса можно проверить корректность указанного кодирования. Аудит внутренних страниц «Анализа сайта» проверяет кодировку сервера и сравнивает ее с той, которая указана на внутренней странице. Найденные ошибки Анализ покажет в результатах проверки, и вы сразу узнаете, где нужно исправить.
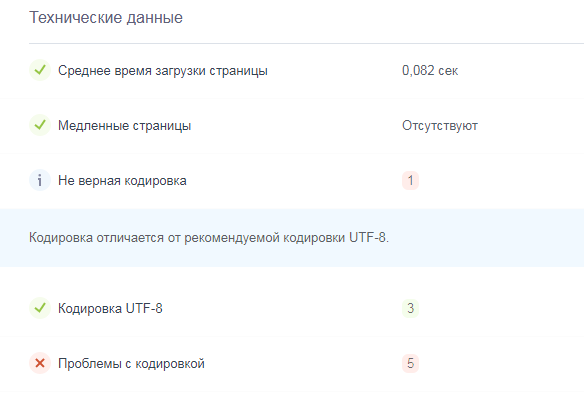 Отчет о технических данных
Отчет о технических данных
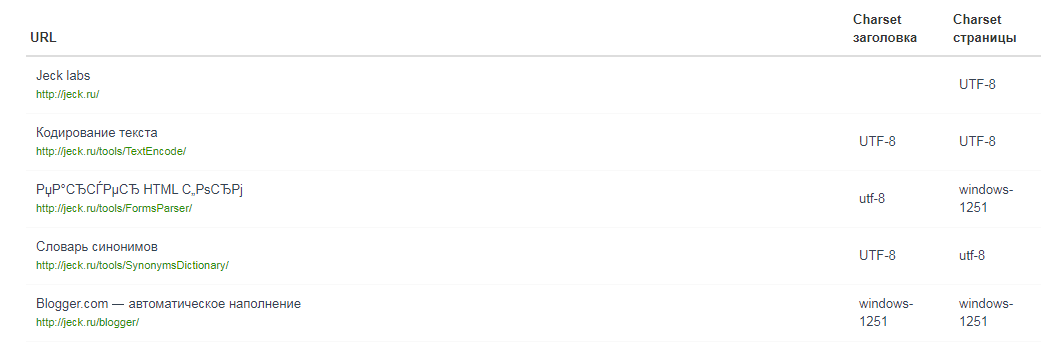 Кодировка сервера и страницы
Кодировка сервера и страницы
Проверить кодировку еще можно через сервис Validator.w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.
 Кодировка сайта в валидаторе
Кодировка сайта в валидаторе
Если валидатор не обнаружит Charset, он покажет ошибку:
 Ошибка указания кодировки
Ошибка указания кодировки
Но валидатор работает не точно: он проверяет только синтаксис разметки, поэтому может не показать ошибку, даже если кодирование указано неправильно.
Работа с картами 1С 4 в 1: Яндекс, Google , 2ГИС, OpenStreetMap(OpenLayers) Промо
С каждым годом становится все очевидно, что использование онлайн-сервисов намного упрощает жизнь. К сожалению по картографическим сервисам условия пока жестковаты. Но, ориентируясь на будущее, я решил показать возможности API выше указанных сервисов:
Инициализация карты
Поиск адреса на карте с текстовым представлением
Геокодинг
Обратная поиск адреса по ее координатами
Взаимодействие с картами – прием координат установленного на карте метки
Построение маршрутов по указанным точками
Кластеризация меток на карте при увеличении масштаба
Теперь также поддержка тонкого и веб-клиента
1 стартмани
Способ 1: 2cyr
Основное предназначение онлайн-сервиса 2cyr заключается в декодировании определенного отрывка текста, однако это не помешает использовать встроенные в него инструменты для определения кодировки, для чего потребуется только скопировать небольшую надпись.
- В самом декодере вставьте скопированный текст в соответствующую форму, используя контекстное меню или горячую клавишу Ctrl + V.
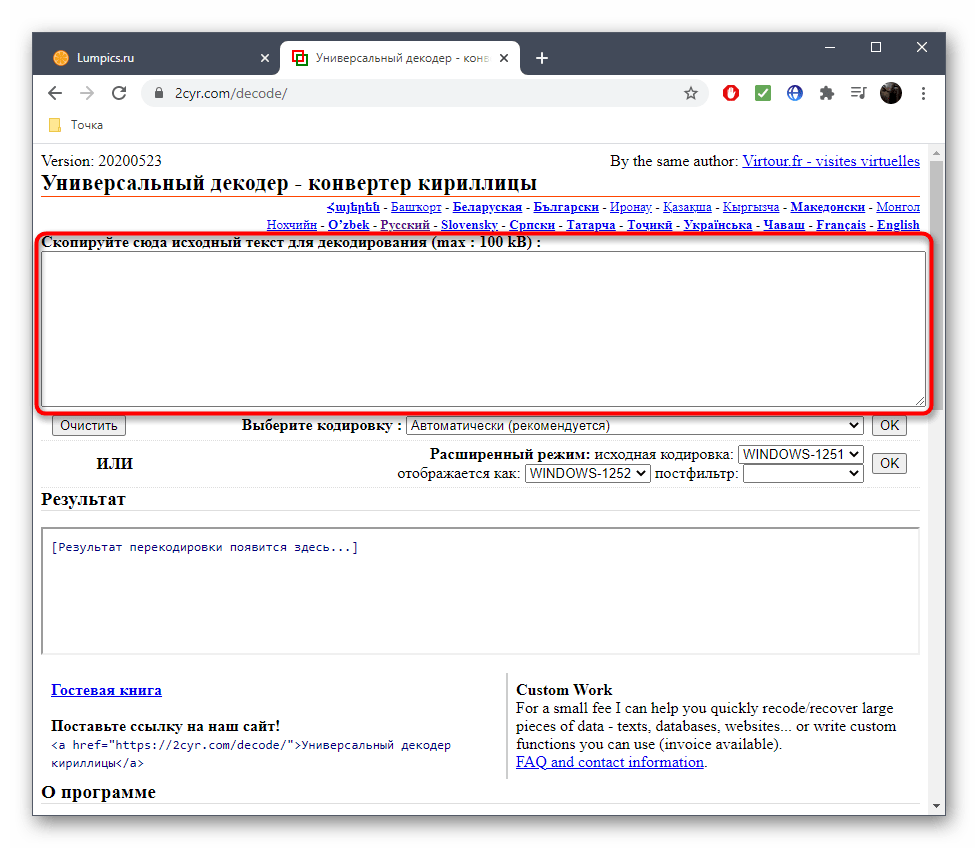
Убедитесь в том, что текст был успешно добавлен, а затем в поле «Выберите кодировку» установите значение «Автоматически (рекомендуется)». Подтвердите распознавание, нажав по кнопке «ОК», которая расположена справа.
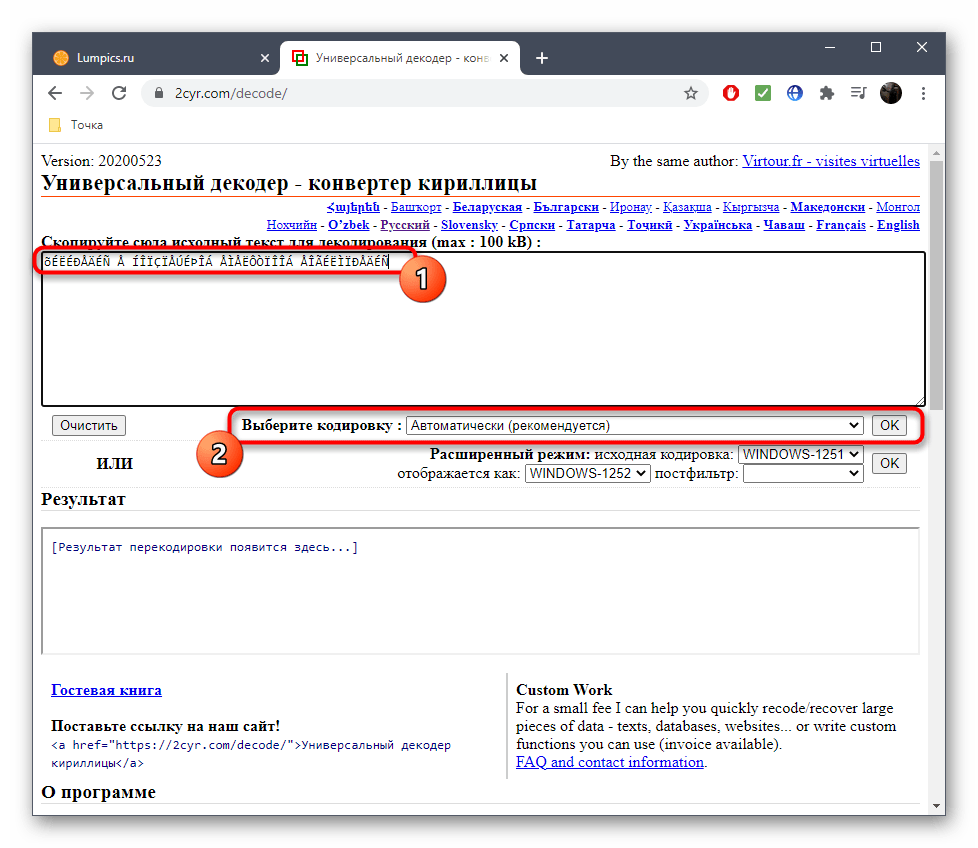
Остается только ознакомиться с названием кодировки в поле «Отображается как», чтобы узнать ее.
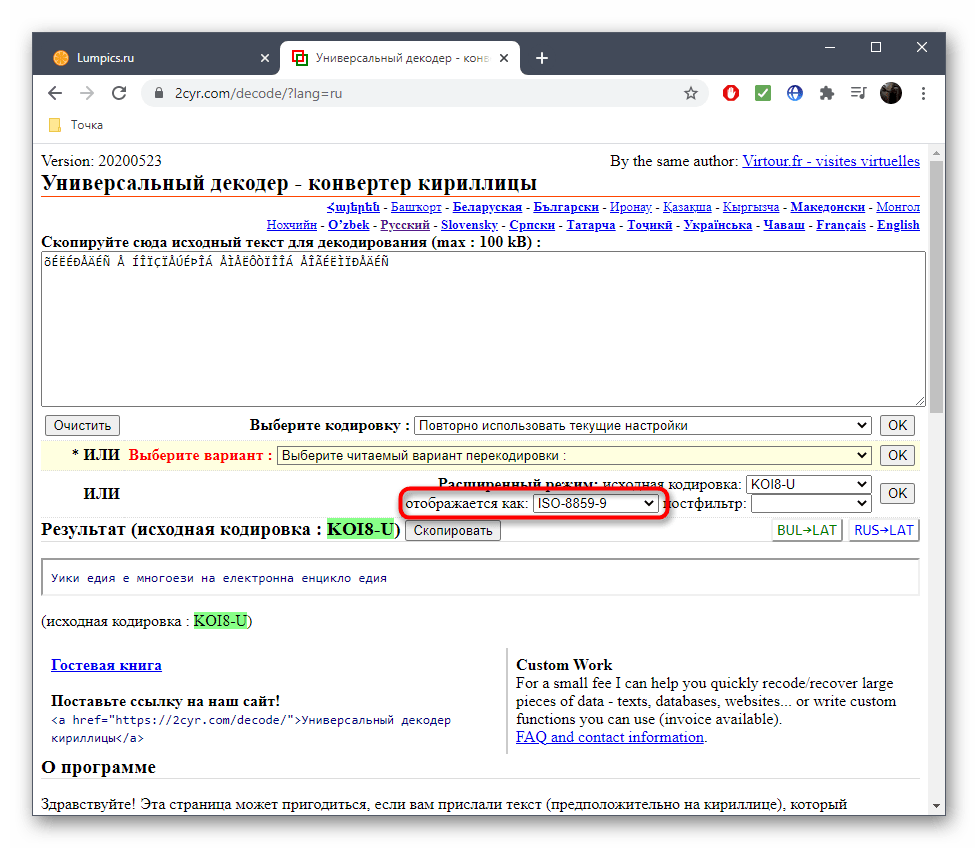
Дополнительно вы можете посмотреть перевод ее в читаемый вид, если та нечитабельна, а также узнать, какая кодировка использовалась для этого.
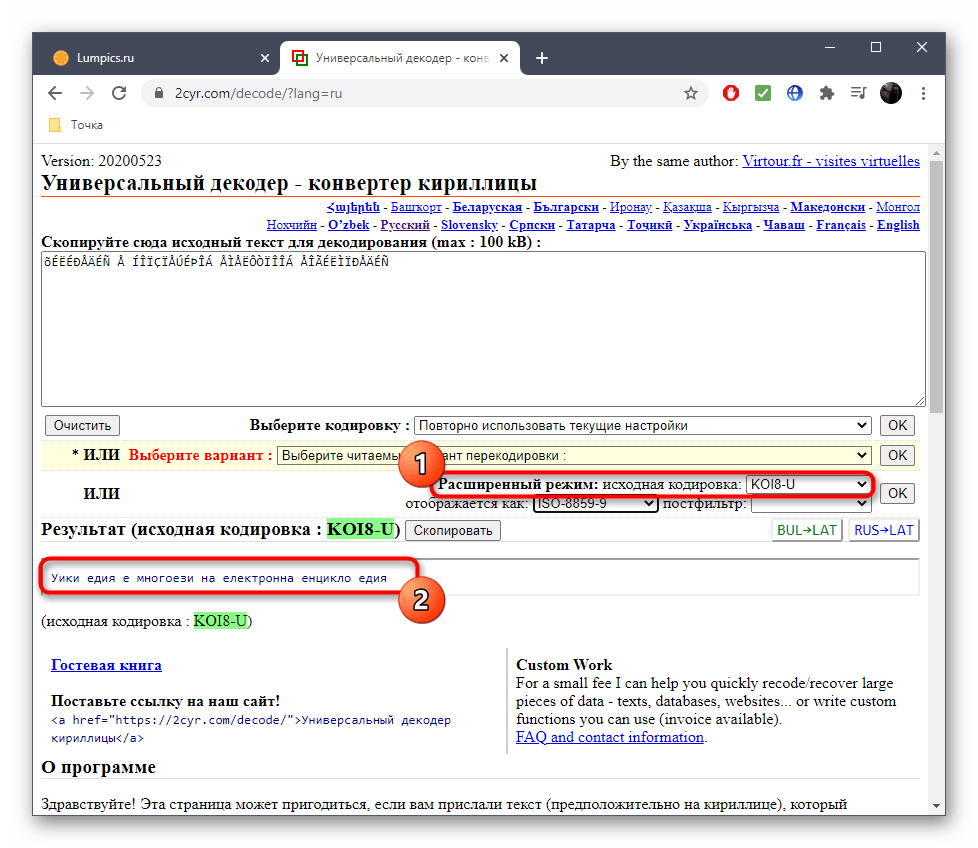
В 2cyr есть и другие читаемые варианты, которые можно использовать в своих целях, переключаясь между ними в соответствующих всплывающих меню.
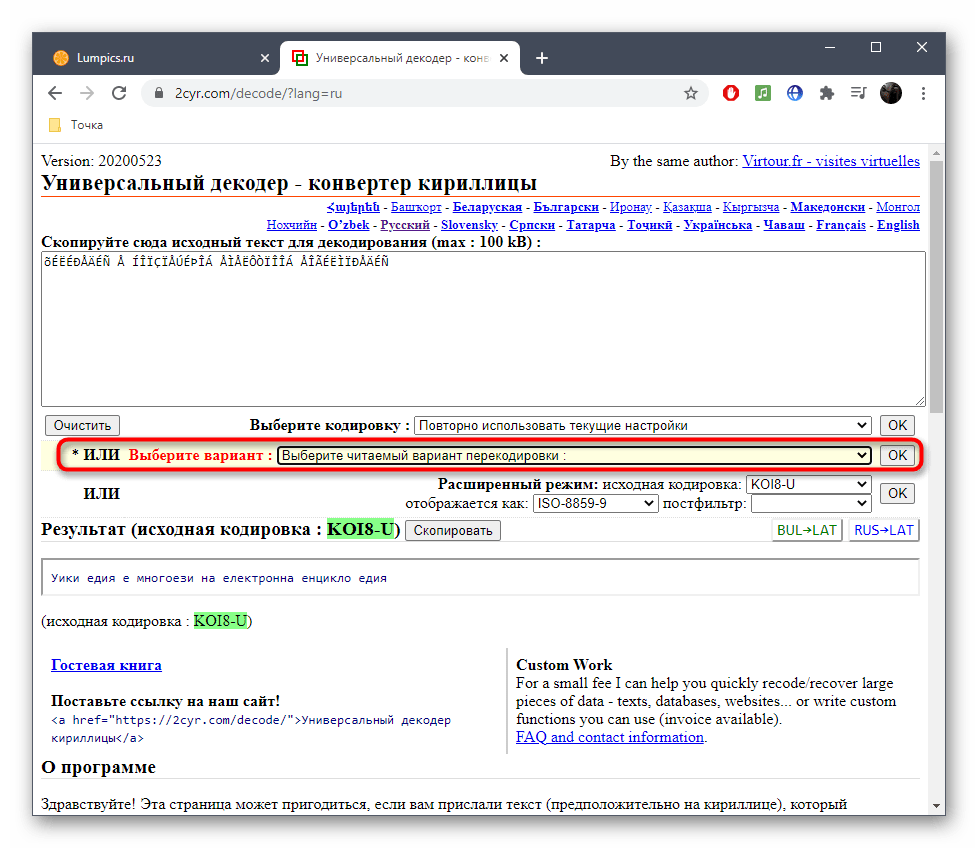
Ничего не помешает сохранить или запомнить этот онлайн-сервис и обращаться к нему в те моменты, когда требуется перевести кодировку или снова определить ее. Если же этот вариант не подходит, переходите к рассмотрению следующих сайтов.
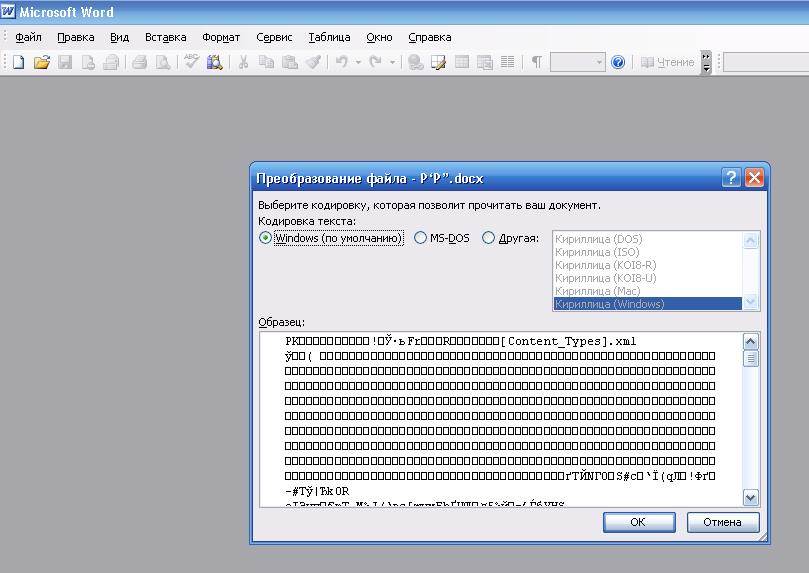




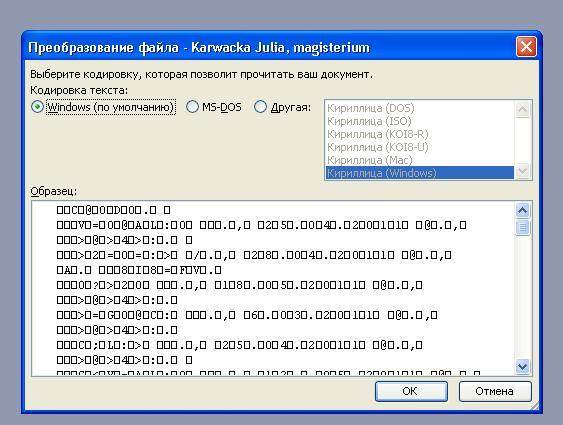
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
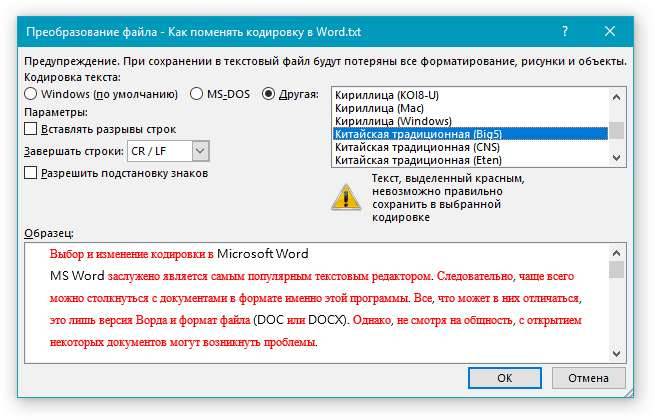
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке “Китайская традиционная (Big5)”. В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание:
Так как Юникод – это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке “Кириллица (Windows)”, текст на иврите не отобразится, а если сохранить его в кодировке “Иврит (Windows)”, то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
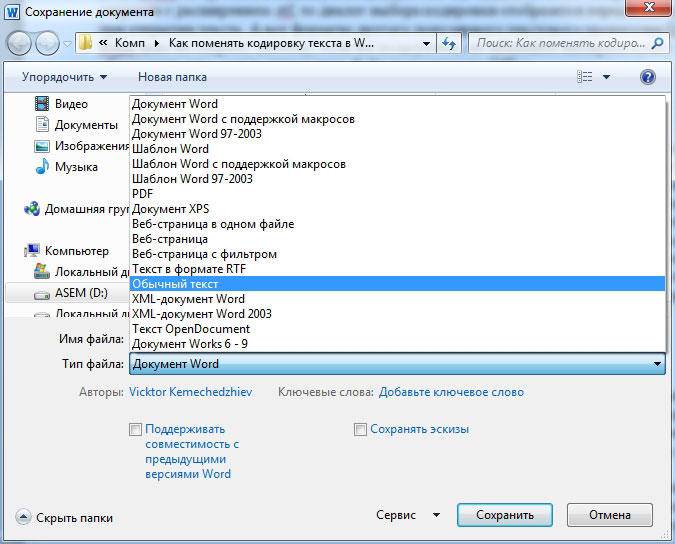
Выбор кодировки
Откройте вкладку Файл
.
В поле Имя файла
введите имя нового файла.
В поле Тип файла
выберите Обычный текст
.
Если появится диалоговое окно Microsoft Office Word – проверка совместимости
, нажмите кнопку Продолжить
.
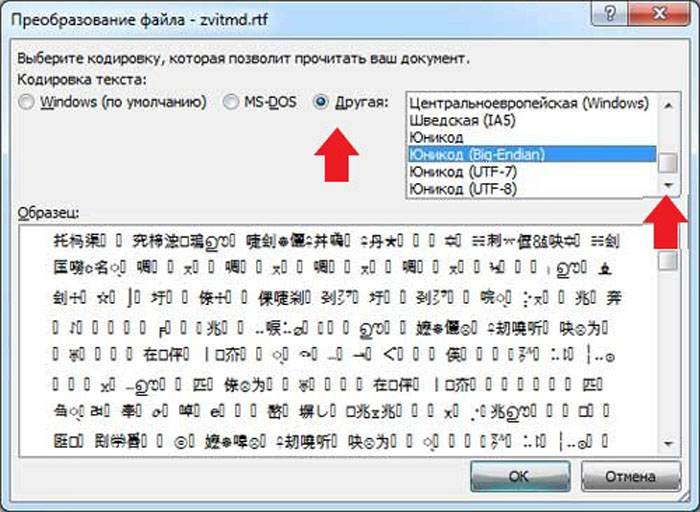
В диалоговом окне Преобразование файла
выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию)
.
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS
.
Чтобы задать другую кодировку, установите переключатель Другая
и выберите нужный пункт в списке. В области Образец
можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание:
Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла
.
Если появилось сообщение “Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке”, можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков
.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки – прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк
и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки
.
2.1 Блочное кодирование
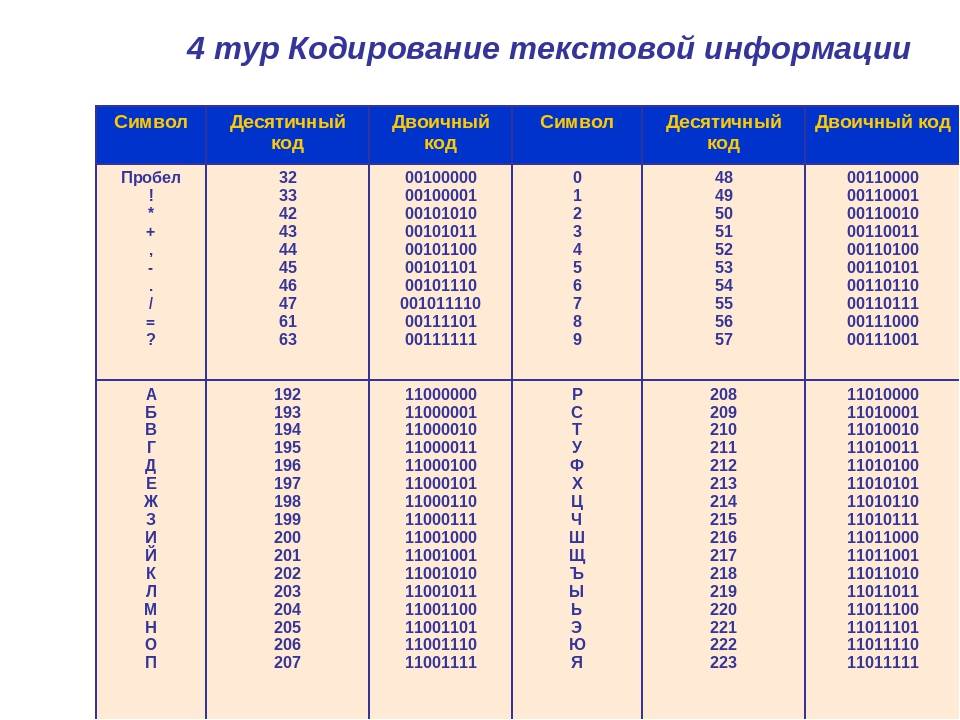
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:
Символ | Количество |
|---|---|
ПРОБЕЛ | 18 |
Р | 12 |
К | 11 |
Е | 11 |
У | 9 |
А | 8 |
Г | 4 |
В | 3 |
Ч | 2 |
Л | 2 |
И | 2 |
З | 2 |
Д | 1 |
Х | 1 |
С | 1 |
Т | 1 |
Ц | 1 |
Н | 1 |
П | 1 |
Всего нами использовано 19 символов (включая пробел). Для хранения в памяти ПК будет затрачено 18+12+11+11+9+8+4+3+2+2+2+2+1+1+1+1+1+1+1=91 байт (91*8=728 бит).


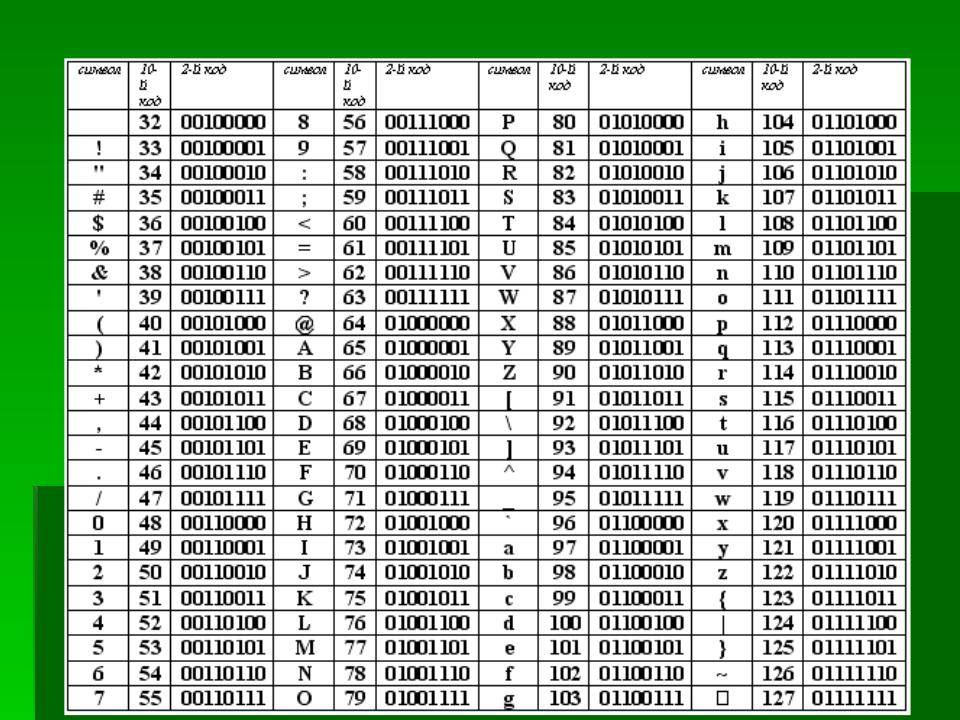



Эти значения мы берём как константы и пробуем изменить подход к хранению блоков. Для этого мы замечаем, что из 256 кодов для символов мы используем только 19. Чтобы узнать – сколько нужно бит для хранения 19 значений мы должны посчитать LOG2(19)=4.25, так как дробное значение бита мы использовать не можем, то мы должны округлить до 5, что нам даёт максимально 32 разных значения (если бы мы захотели использовать 4 бита, то это дало бы лишь 16 значений и мы не смогли бы закодировать всю строку).
Нетрудно посчитать, что у нас получится 91*5=455 бит, то есть зная контекст и изменив способ хранения мы смогли уменьшить использование памяти ПК на 37.5%.
К сожалению такое представление информации не позволит его однозначно декодировать без хранения информации о символах и новых кодах, а добавление нового словаря увеличит размер данных. Поэтому подобные способы кодирования проявляют себя на бОльших объемах данных.
Кроме того, для хранения 19 значений мы использовали количество бит как для 32 значений, это снижает эффективность кодирования.
Общие сведения о кодировке текста
Информация, которая выводится на экран в виде текста, на самом деле хранится в текстовом файле в виде числовых значений. Компьютер преобразует эти значения в отображаемые знаки, используя кодировку.
Кодировка – это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке “Кириллица (Windows)” знаку “Й” соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка “Кириллица (Windows)”, компьютер считывает число 201 и выводит на экран знак “Й”.
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка “Западноевропейская (Windows)”, знак “Й” из исходного текстового файла на основе кириллицы будет отображен как “É”, поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.
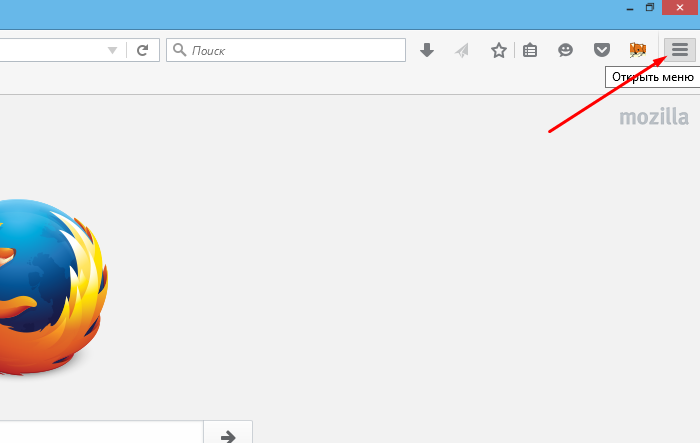 Нажимаем по иконке из трех линий в правом верхнем углу
Нажимаем по иконке из трех линий в правом верхнем углу
Шаг 2. В контекстном меню запустить «Настройки».
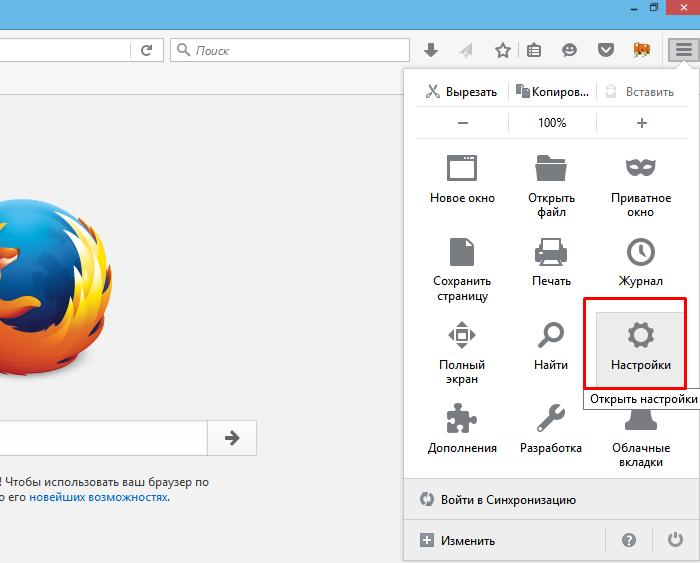 Открываем «Настройки»
Открываем «Настройки»
Шаг 3. Перейти во вкладку «Содержимое».
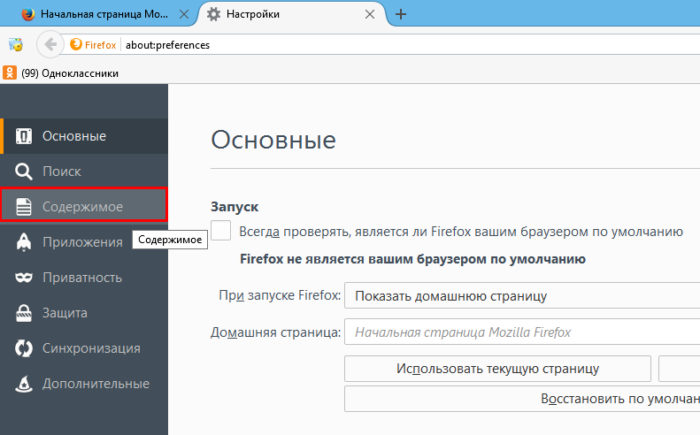 Переходим во вкладку «Содержимое»
Переходим во вкладку «Содержимое»
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».
 В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
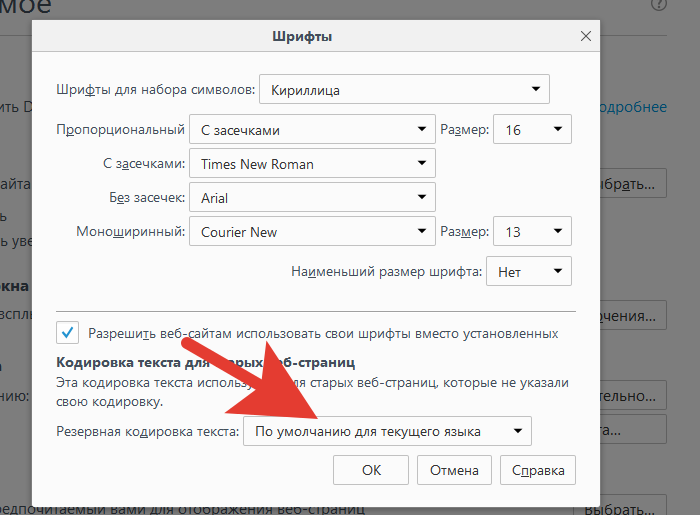 Нажимаем на название кодировки
Нажимаем на название кодировки
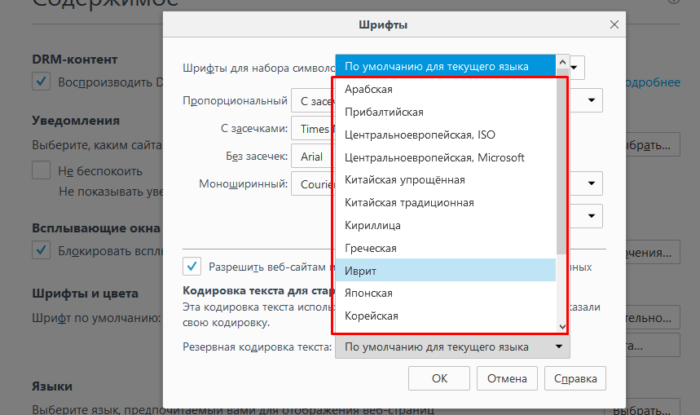 Выбираем подходящую кодировку, нажимаем «ОК»
Выбираем подходящую кодировку, нажимаем «ОК»
Compliance status
We firmly believe that the internet should be available and accessible to anyone, and are committed to providing a website that is accessible to the widest possible audience,
regardless of circumstance and ability.
To fulfill this, we aim to adhere as strictly as possible to the World Wide Web Consortium’s (W3C) Web Content Accessibility Guidelines 2.1 (WCAG 2.1) at the AA level.
These guidelines explain how to make web content accessible to people with a wide array of disabilities. Complying with those guidelines helps us ensure that the website is accessible
to all people: blind people, people with motor impairments, visual impairment, cognitive disabilities, and more.
This website utilizes various technologies that are meant to make it as accessible as possible at all times. We utilize an accessibility interface that allows persons with specific
disabilities to adjust the website’s UI (user interface) and design it to their personal needs.
Additionally, the website utilizes an AI-based application that runs in the background and optimizes its accessibility level constantly. This application remediates the website’s HTML,
adapts Its functionality and behavior for screen-readers used by the blind users, and for keyboard functions used by individuals with motor impairments.